Keyword [Bi-LSTM] [Prototypical Network] [Attention LSTM]
Snell J, Swersky K, Zemel R. Prototypical networks for few-shot learning[C]//Advances in Neural Information Processing Systems. 2017: 4077-4087.
1. Overview
1.1. Motivation
- human can visualize or imagine what novel objects look like from different views

In this paper, it proposes a novel approach to low-shot learning (learning concept from few examples)
- build on recent progress in meta-learning (learning to learn)
- combine a meta-learner with a hallucinator producing additional training examples
- optimize both model jointly
- proposed hallucinator can be incorporated into a variety of meta-learners
1.2. Low-shot Learning
- build generative models that can share priors across categories
- build feature representation that are invariant to intra-class variation
- triplet loss, contrastIve loss
1.3. Meta Learning
- try to frame low-shot learning as a ‘learning to learn’ task
- train a parametrized mapping from training sets to classifiers
- learner embeds examples into a feature space
- accumulate statistics over training set using RNN, MAN, MLP
1.3.1. Definition
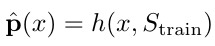
- x. test sample
- S_train. training set
- p. prediction
- h. classification algorithm

- meta-learning is an umbrella term
- estimate w can be construed as meta-learning
1.3.2. Stage-1. Meta Training
- estimate w
- meta-learner has access to a large labeled dataset S_meta
- in each iteration, sample a classification problem out of S_meta
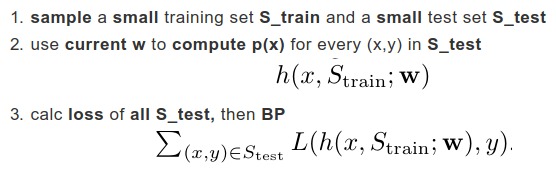
- m. the number of class in each iteration
- n. maximum number of training examples per clas
1.3.3. Stage-2. Meta Testing
- the labeled training set and unlabeled test examples are given to the algorithm h
- then algorithm h output class probabilities
1.3.4. Prototypical Networks (PN)
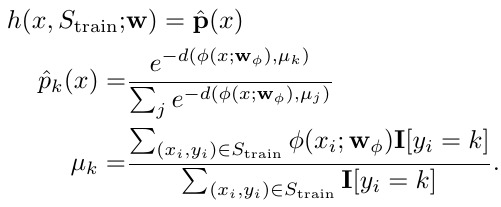
- d. distance metric
- w_phi. learned feature extractor
1.3.5. Matching Network (MN)

- embed all training and test points independently using feature extractor
- create a contextual embedding of training and test examples using bi-LSTM and attention-LSTM
- three parameters. w_phi, w_g and w_f
1.3.6. Prototype Matching Networks (PMN)
- in MN, attention LSTM might find it harder to attend to rare classes
- combine contextual embedding in MN with the resilience to class imbalance in PN
- collapse every class to its class mean
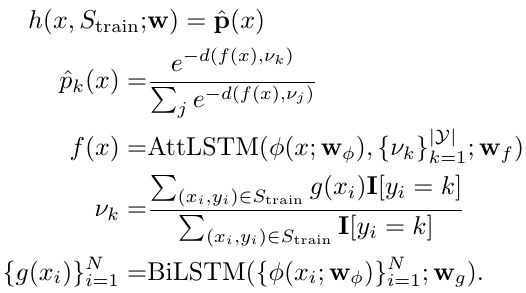
1.4. Meta-Learning with Learned Hallucination
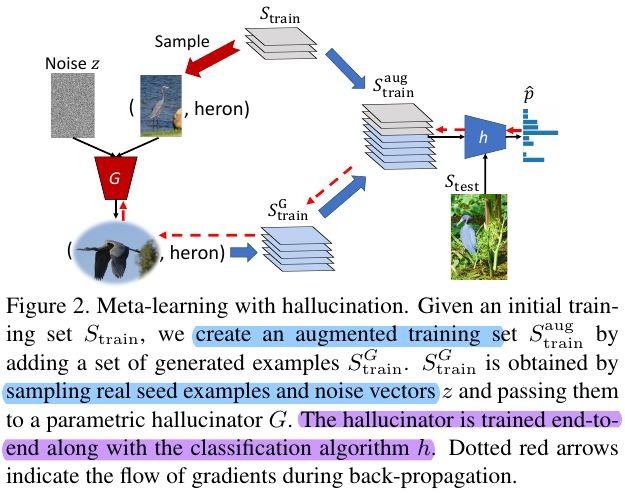
1.4.1. Meta-Training
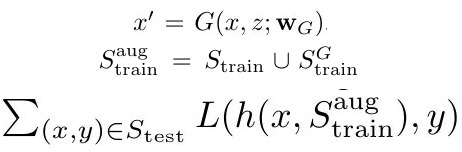
- BP final loss and update h and G jointly
1.4.2. Meta-Testing
- hallucinator (G) keeps fixed
1.4.3. Tradeoffs between Base and Novel Classes
normal.

prior knowledge.
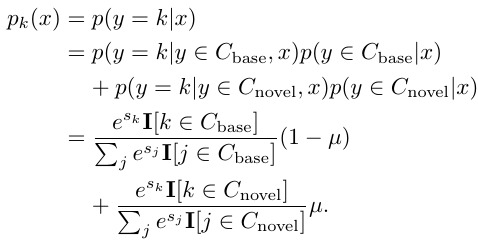
overall accuracy remains fairly stable, even as novel class accuracy rises and base class accuracy falls

1.4.4. New Evaluation
- test examples from novel classes. μ=1
- from base classes
- from both
2. Experiments
2.1. Details
- train extractor on C_base, then save all feature to disk
- ResNet-10 and ResNet-50
2.1.1. Meta-learner Architecture
- PN. 2 MLP + ReLU
- MN. 1 bi-LSTM for training examples, 1 attention LSTM for test samples
- PMN same as MN
2.1.2. Hallucinator Architecture
- 3 MLP + ReLU
- all hidden layers. 512 for ResNet-10, 2048 for ResNet-50
- initialization. block diagonal identity matrices to copy seed example
2.2. Comparison
